На практике, хотя для каждого элементарного типа есть соответствующий объект, использовать их не рекомендуется. Это - отмершая часть языка.
var ok = new Boolean(true) // не надо
Элементарные типы автоматически интерпретируются как объекты при вызовах методов, поэтому можно, определять длину строки как:
alert("Апельсин".length)
Поэтому иногда говорят, что в javascript - все объекты. Так удобно думать, но определенная разница все же есть.
Например, typeof выдаст разный результат:
alert(typeof "test")
alert(typeof new String("test"))
Это - еще одна причина избегать использования объектов там, где существует элементарный тип: меньше путаницы.
Преобразование типа можно явным образом сделать через его название:
var test = Boolean("something") // true
Кроме всем известных типов данных - в javascript есть специальное значение undefined, которое, условно говоря, обозначает что "данных нет". Не null, а данных нет. Понимайте как хотите.
Далее рассмотрим особенности каждого из этих типов.
При операциях с Number - никогда не происходят ошибки. Зато могут быть возвращены специальные значения:
1/0
Number.POSITIVE_INFINITY (плюс бесконечность)
-1/0
Number.NEGATIVE_INFINITY (минус бесконечность)
Number(“something”)
NaN (Not-a-Number, результат ошибочной операции)
Бесконечность бывает полезно использовать в обычном коде. Например, положительная бесконечность Number.POSITIVE_INFINITY больше любого Number, и даже больше самой себя.
По поводу строчки "Все числа хранятся в формате double word, т.е 8 байт. В этом формате невозможны точные вычисления." под загаловком "Number\Неточные вычисления" есть пара замечаний: word (и double word, соответственно) не предполагает возможности хранить дробные и отрицательные числа, только положительные целые в любом языке программирования, и предполагает только точные вычисления... А тут, судя по всему, используется real64 - восьмибайтная вещественная переменная, в которой значение каждого бита далеко не так очевидно как в целочисленных...
А вот на всеми нами горячо любимой архитектуре x86 (внезапно, да?) word всегда считался равным 16 битам. И кто тут, спрашивается, врет: правило или системные хедеры?
В памяти машины все вещественные числа хранятся в определенном количестве байт, и из-за кратности значения всегда существует неточность между вводимым значением (тем что мы используем в коде) и тем что находится в памяти.
Подробнее на wiki или в google на тему хранение данных в памяти компьютера.
Единственный реальный вариант:
1) округлять до разумного кол-ва знаков после запятой
Принципиальное решение:
2) отказаться от дробных чисел
Или:
3) отказаться от математики на клиенте. В PHP есть библиотека BCMath в которой можно считать с произвольной точностью. Принцип - отказ от двоичной системы и вычисления на основе представления чисел как последовательности символов по алгоритмам сложения и т.п. в столбик.
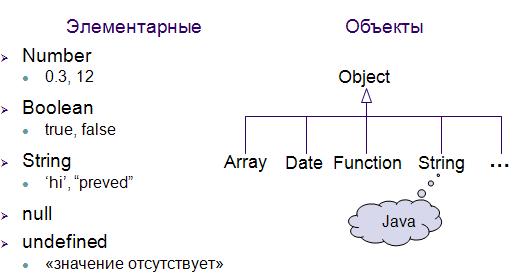
Не совсем корректный рисунок, т.к. Number, Boolean и String это объекты-обертки, простые типы именуются с маленькой буквы: т.е. соответственно number, boolean, string.
По результатам операции typeof для null или undefined можно заключить, что это не элементарные типы, а объектные, так как результат выводится как object. Смею предположить, что интерпретатор при анализе выражения, например var n = null, невидимым образом создает объект, согласно литералу null, как это делается в Java. Поэтому на мой взгляд элементарных типов три: number, boolean и string. Если не прав, то поправьте меня:)
null и undefined - это "значения", а не типы. Соответственно у значений тип есть, но он ни string, ни boolean, ни number. Конечно, хорошо бы перечитать спецификацию ECMA на эту тему, но замечу, что реализации - по-разному "хромают" на эту тему.
Здравствуйте, как проверить, что Number.POSITIVE_INFINITY больше самого себя например? Если пишу if (Number.POSITIVE_INFINITY == 1/0) ... или, например, if (1/0 == 2/0) ..., то результат true.
Деления любого числа на ноль даёт в результате значение Number.POSITIVE_INFINITY. Разумеется, оно всегда будет равно само себе, так же как сравнивать бесконечности - бессмысленно по определению.
Статьи интересные. Но мне кажеться, что было бы неплохо к каждой статье подготовить практические задания. Что бы на практике закрепить пройденный материал. И правильные решения где-то показывать.
Здравстуйте помогите пожалуйста!Ввожу 100 выводит слово ошибка.Что не так вот код
var pricePattern = "^[0-9]*$";
var errorMessage = "";
function checkPrice(price)
{
if(!price.match(pricePattern)) {
alert("ошибка");
errorMessage +="*" + errorPrice + "\n";
}
}
function parseBool(str) {
n = parseInt(str); // пробуем преобразовать в число
if (isNaN(n)) { // если не удалось, проверим на "true"/"false"
switch (str.toLowerCase()) {
case "true": return true;
case "false": return false;
} }
else return (n != 0); // строка преобразована в число; ненулевое значение вернет true, нулевое - false
// Сюда можно вставить return со значением, возвращаемым по умолчанию,
// или поместить его в ветку default в switch.
// В противном случае (как здесь) при неудаче парсинга
// результатом функции будет undefined.
}
parseBool("True") === true
parseBool("1") === true
parseBool("115") === true
parseBool("false") === false
parseBool("FALSE") === false
parseBool("0") === false
parseBool("gh3hff4") === undefined
parseBool("true!") === undefined // неудача: сравнение осуществляется со всей строкой, а не с ее началом; пофиксить несложно
parseBool(" false") === undefined // неудача: пробел - тоже символ; пофиксить чуть сложнее
parseBool("1!!!") === true // у функции parseInt свои правила
parseBool(" 1") === true // аналогично
Строго говоря, функция сработает предсказуемо только если аргумент является строкой. Но если применять ее заведомо только для строк фиксированного формата, то дополнительные проверки и вычисления не нужны.
Обертки иногда создаются неявно, например, когда мы обращаемся к методу или свойству переменной:
var s = 'qqqqq';
alert(s.charAt(1));
s.aaa = 23;
здесь в обоих случаях создается временная обертка. charAt берется из ее прототипа и работает как ожидалось. Присвоение .aaa так же делается для временного объекта, и потому будет утеряно вместе с ним по окончании операции (alert(s.aaa) покажет undefined).
Автору статьи - добавьте в пункт toFixed примечание, что данный метод может также возвращать неверный результат. В примере выше со сложением 0,1 и 0,2 появляется излишек 4*10^(-17) - при округлении до двух знаков после запятой это не имеет значения в большинстве случаев (кроме округления до наименьшего целого, большего или равного исходному числу). Но в одном из моих опытов ошибка была порядка 1*10^(-2), что гораздо ощутимее (в миллион миллиардов раз). Вероятно, единственный гарантированный способ избежать подобных явлений - действительно пользоваться целочисленным исчислением - т.е. сначала привести число к целому типу, потом произвести вычисления, затем отделить необходимое количество знаков после запятой.
В памяти машины все вещественные числа хранятся в определенном количестве байт, и из-за кратности значения всегда существует неточность между вводимым значением (тем что мы используем в коде) и тем что находится в памяти.
Подробнее на wiki или в google на тему хранение данных в памяти компьютера


По поводу строчки "Все числа хранятся в формате double word, т.е 8 байт. В этом формате невозможны точные вычисления." под загаловком "Number\Неточные вычисления" есть пара замечаний: word (и double word, соответственно) не предполагает возможности хранить дробные и отрицательные числа, только положительные целые в любом языке программирования, и предполагает только точные вычисления... А тут, судя по всему, используется real64 - восьмибайтная вещественная переменная, в которой значение каждого бита далеко не так очевидно как в целочисленных...
Да, float64. Поправлено. Вот выдержка из исходников SpiderMonkey с точным определением типа:
js/src/jspubtd.h
[c]
typedef uint16 jschar;
typedef int32 jsint;
typedef uint32 jsuint;
typedef float64 jsdouble; // оно
typedef jsword jsval;
typedef jsword jsid;
[/c]
Собственно, double word = 4 байта

Собственно, word - это машинное слово, и его длина равна разрядности машины
А вот на всеми нами горячо любимой архитектуре x86 (внезапно, да?) word всегда считался равным 16 битам. И кто тут, спрашивается, врет: правило или системные хедеры?
Еще есть такая полезная штука, как Number.toFixed.
А вот IE 5.0 (уже к счастью почти совсем не актуальный) такого не умеет...
Кстати, в хроме эта функция тоже не работает - ничего не выводится. Хотя тот же файл в мозилле работает корректно, и ошибки не выдаются.
У меня в хроме получилось сделать так:
Не объясните подробнее что делает ваше выражение:
"превед медвед".replace(/(.*?)\s(.*)/, "$2, $1!") // => медвед, превед!
Спасибо
присоединяюсь к Minh. Поясните, плз.
Этот вызов захватит в первую скобку слово "превед", а во вторую - "медвед", затем заменит их на $2, $1 - то есть, на "медвед, превед".
Более подробно про регулярные выражения вы можете прочитать в статье
Регулярные выражения.
Результат: 0.3000000004... Это как?
В памяти машины все вещественные числа хранятся в определенном количестве байт, и из-за кратности значения всегда существует неточность между вводимым значением (тем что мы используем в коде) и тем что находится в памяти.
Подробнее на wiki или в google на тему хранение данных в памяти компьютера.
Гораздо интереснее, как это обойти
Есть рецепты?
Единственный реальный вариант:
1) округлять до разумного кол-ва знаков после запятой
Принципиальное решение:
2) отказаться от дробных чисел
Или:
3) отказаться от математики на клиенте. В PHP есть библиотека BCMath в которой можно считать с произвольной точностью. Принцип - отказ от двоичной системы и вычисления на основе представления чисел как последовательности символов по алгоритмам сложения и т.п. в столбик.
Ради клиентских вычислений напрягать сервер - дороговато будет, если это не сложная математика, а 0,1+0,2 )))
Есть такой вариант http://sourceforge.net/projects/bcmath-js/ - пока ещё не использовал, но планирую в скорости опробовать
А есть ещё такой вариант: (1+2)/10
Почему true, а не false?
Перечитайте, пожалуйста еще раз статью.
А вообще все грубо говоря "ненулевые элементы", точнее элементы имеющие значение отличное от:
false
null
undefined
“”
0
Number.NaN
имеют значение true
Это сделали для вашего же удобства.
Чтобы можно было кратко писать
if (mystr) { ... }Подразумевая: "если в mystr что-то есть"
Даже в случае:
var res=Boolen("false")//true
В случае:
var res=Boolen('''')//false
(любая непустая строка-true)
потому что вот этот твой test - это НЕ пустая строка
var test = Boolean("") alert(test) var test1 = Boolean("Something") alert(test1)Заранее спасибо!
Вы не поясните что вы имели в виду? А то знаете, все слова понятны, но ничего не понятно
прогуглите "Регулярные выражения" для понимания смысла данных слов. довольно полная информация также присутствует на wiki.
Интересная статья, много полезных мелочей, которые нельзя узнать, изучая язык по чужим скриптам и примерам =).
скажите, от куда parseInt("010") = 8 //
восемь? 010 - это два в 2х ричной системе
А кто говорил про двоичную? Речь идет о восьмеричной.
напугал человека, он то поди знает только двоичную, десятичную и шестнадцатеричную
Не совсем корректный рисунок, т.к. Number, Boolean и String это объекты-обертки, простые типы именуются с маленькой буквы: т.е. соответственно number, boolean, string.
По результатам операции typeof для null или undefined можно заключить, что это не элементарные типы, а объектные, так как результат выводится как object. Смею предположить, что интерпретатор при анализе выражения, например var n = null, невидимым образом создает объект, согласно литералу null, как это делается в Java. Поэтому на мой взгляд элементарных типов три: number, boolean и string. Если не прав, то поправьте меня:)
null и undefined - это "значения", а не типы. Соответственно у значений тип есть, но он ни string, ни boolean, ни number. Конечно, хорошо бы перечитать спецификацию ECMA на эту тему, но замечу, что реализации - по-разному "хромают" на эту тему.
Здравствуйте, как проверить, что Number.POSITIVE_INFINITY больше самого себя например? Если пишу if (Number.POSITIVE_INFINITY == 1/0) ... или, например, if (1/0 == 2/0) ..., то результат true.
Что означает "больше самого себя"? Это как?
Деления любого числа на ноль даёт в результате значение Number.POSITIVE_INFINITY. Разумеется, оно всегда будет равно само себе, так же как сравнивать бесконечности - бессмысленно по определению.
А там в статье так написано
Статьи интересные. Но мне кажеться, что было бы неплохо к каждой статье подготовить практические задания. Что бы на практике закрепить пройденный материал. И правильные решения где-то показывать.
Уважаемый, а про date не забыли?
Здравстуйте помогите пожалуйста!Ввожу 100 выводит слово ошибка.Что не так вот код
var pricePattern = "^[0-9]*$";
var errorMessage = "";
function checkPrice(price)
{
if(!price.match(pricePattern)) {
alert("ошибка");
errorMessage +="*" + errorPrice + "\n";
}
}
Думаю, стоит почитать о регулярных выражениях в JavaScript.
var pricePattern = "^[0-9]*$"; var errorMessage = ""; function checkPrice(price){ // привести к строке необходимо if(typeof price!="string" ) price = (price).toString() if(!price.match(pricePattern)) { alert("ошибка"); errorMessage +="*" + errorPrice + "\n"; } } checkPrice(100)Запускаю в хроме:
Получаю сначала "boolean", потом "string". Почему так?
Кстати, в firefox у меня такого не наблюдается - выводится оба раза boolean.
Сам себе отвечаю. Так как код в глобальном контексте, то var status означает window.status (статусная строка в браузере, которая всегда string).
Как все же правильно парсить строку "True" в булево значение?
function parseBool(str) { n = parseInt(str); // пробуем преобразовать в число if (isNaN(n)) { // если не удалось, проверим на "true"/"false" switch (str.toLowerCase()) { case "true": return true; case "false": return false; } } else return (n != 0); // строка преобразована в число; ненулевое значение вернет true, нулевое - false // Сюда можно вставить return со значением, возвращаемым по умолчанию, // или поместить его в ветку default в switch. // В противном случае (как здесь) при неудаче парсинга // результатом функции будет undefined. } parseBool("True") === true parseBool("1") === true parseBool("115") === true parseBool("false") === false parseBool("FALSE") === false parseBool("0") === false parseBool("gh3hff4") === undefined parseBool("true!") === undefined // неудача: сравнение осуществляется со всей строкой, а не с ее началом; пофиксить несложно parseBool(" false") === undefined // неудача: пробел - тоже символ; пофиксить чуть сложнее parseBool("1!!!") === true // у функции parseInt свои правила parseBool(" 1") === true // аналогичноСтрого говоря, функция сработает предсказуемо только если аргумент является строкой. Но если применять ее заведомо только для строк фиксированного формата, то дополнительные проверки и вычисления не нужны.
сейчас кто тут есть?
Пару слов насчет оберток для простых типов.
Обертки иногда создаются неявно, например, когда мы обращаемся к методу или свойству переменной:
здесь в обоих случаях создается временная обертка. charAt берется из ее прототипа и работает как ожидалось. Присвоение .aaa так же делается для временного объекта, и потому будет утеряно вместе с ним по окончании операции (alert(s.aaa) покажет undefined).
второй случай - следствие первого
String.prototype.myfunc = function() { alert(typeof this); // 'object' }; s.myfunc();третий случай - apply/call
function myfunc() { alert(typeof this); // снова 'object' } myfunc.call(s); myfunc.apply(s);Автору статьи - добавьте в пункт toFixed примечание, что данный метод может также возвращать неверный результат. В примере выше со сложением 0,1 и 0,2 появляется излишек 4*10^(-17) - при округлении до двух знаков после запятой это не имеет значения в большинстве случаев (кроме округления до наименьшего целого, большего или равного исходному числу). Но в одном из моих опытов ошибка была порядка 1*10^(-2), что гораздо ощутимее (в миллион миллиардов раз). Вероятно, единственный гарантированный способ избежать подобных явлений - действительно пользоваться целочисленным исчислением - т.е. сначала привести число к целому типу, потом произвести вычисления, затем отделить необходимое количество знаков после запятой.
неправда! (Number.POSITIVE_INFINITY > Number.POSITIVE_INFINITY) === false
Вообще -то == и === - это РАЗНЫЕ способы сравнения, и потому неудивительно, если они выдадут разные результаты.
плиз кто нибудь скажет как вписать своё имя в java картинку?
Почему так?
alert(-0) тоже будет 0.
Проверьте, пожалуйста
У меня получилось false, false, true. Хотя по мне было бы логичным всегда false, ну или maybe
Для проверки типа данных не используйте instanceof, он работает ТОЛЬКО с объектами:
console.log(true instanceof Boolean); // false console.log(0 instanceof Number); // false console.log("" instanceof String); // false console.log([] instanceof Array); // true console.log({} instanceof Object); // trueДля ПРАВИЛЬНОГО определения типа данных я использую:
function typeOf(value) { return Object.prototype.toString.call(value).slice(8, -1); } console.log(typeOf(true)); // Boolean console.log(typeOf(0)); // Number console.log(typeOf("")); // String console.log(typeOf([])); // Array console.log(typeOf({})); // Object console.log(typeOf(null)); // Null console.log(typeOf(undefined)); // Undefined console.log(typeOf(function(){})); // Function var sdfgsdfg; console.log(typeOf(sdfgsdfg)); // UndefinedЯваскрипт сам меняет тип переменной в зависимости от операции:
ps: надеюсь кому-то помог
Подскажите, есть ли встроенный способ замены регистра строки? Т.е. на входе "МедвеД", на выходе "медвед" или "МЕДВЕД".
Отвечу сам себе
Функция .toLowerCase()
пример: string = string.toLowerCase();
Javascript есть и объектные типы данных и элементарные, которые можно интерпретировать как объекты.
В памяти машины все вещественные числа хранятся в определенном количестве байт, и из-за кратности значения всегда существует неточность между вводимым значением (тем что мы используем в коде) и тем что находится в памяти.
Подробнее на wiki или в google на тему хранение данных в памяти компьютера