
30.07.2024, 23:10
|
 |
Профессор



|
|
Регистрация: 19.01.2012
Сообщений: 499
|
|
seregadushka,
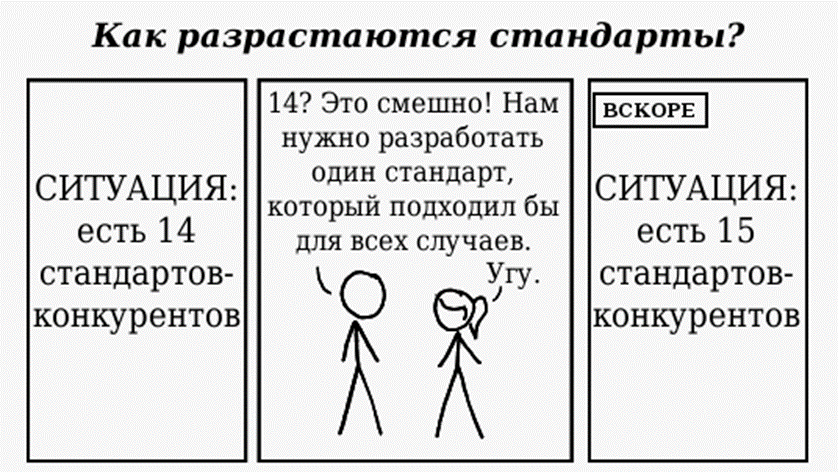
Не существует никакой единственной кодировки на все случаи жизни, у всех есть какие-то недостатки. В случае UTF-8 - это переменная длина символов, что сильно осложняет работу: чтоб скопировать 1000 символов, нельзя просто взять 1000*X байт, нужно прямо посимвольно читать весь текст. И то же самое для простого перехода к 100500-му символу.
От того, что UTF-8 стала стандартом, остальные кодировки не перестали быть такими же стандартами:
|
|
30.07.2024, 23:32
|
 |
Тлен
|
|
Регистрация: 02.01.2010
Сообщений: 6,618
|
|
|
seregadushka, потому что обратная совместимость. Никто не будет рисковать отвалом десятой части интернета. Подвижки в сторону "одна кодировка чтоб править ими всеми" идут, но до следующего глобального изменения интернета, типа смены эпохи web 2.0, можно ничего не ждать.
__________________
29375, 35
|
|
31.07.2024, 01:02
|
 |
Аспирант
|
|
Регистрация: 10.07.2024
Сообщений: 55
|
|
|
Белый шум, не ожидал такую древность сейчас услышать.
коллеги, я слышал про эти разговоры , про переменную длину символов , еще когда интернет был по телефону ! Это тогда кодировали по 1 байту ради экономии на дискетах.
Я даю тебе гарантию . что сейчас нет никакой последовательного чтения.
UTF-8, -16, -32 имеет 4 байта на каждый символ. У всех троих одинаково. Это мы имеем 2^32 буков максимально, в теории это 4,3 млрд штук.
В UTF-32 просто нет служебных отдельных символов и места под них. Все загнано в коды самих символов, по 4 байта на каждый, а внутри уже там как-то распределяетя. Место на все хватает, с запасом.
все кратко в Wики есть. может, я неправильно понимаю, У UTF-8 вроде как ограничение на 2^21 буков. Но и так понятно, что как ни ограничивай на все языки места хватит.
Разница в в количестве служебных символов. Условно UTF-8 из этого 2^32 половина приходится на служебные биты.
как они их там используют - это уже их дело. Понятно, что оставшихся 2^16 битов нам на буквы за глаза хватит.
Я про то, что даже тогда , в 1991 году уже понимали, что экономия на спичках, на переменной длине символов -- это тупик и глупость. А сейчас тем более, никто эту переменную длину не поддерживает.
Последний раз редактировалось seregadushka, 31.07.2024 в 01:05.
|
|
31.07.2024, 01:13
|
|
Аспирант
|
|
Регистрация: 10.07.2024
Сообщений: 55
|
|
|
Если в Wiki на странице UTF-8 нет такой последовательности букв "последовательное чтение" -- значит, нет.
И не надо тянуть эти старые вредные теории и заблуждения через поколения дальше.
А то распугаете молодежь с форума.
|
|
31.07.2024, 01:44
|
|
Аспирант
|
|
Регистрация: 10.07.2024
Сообщений: 55
|
|
Все . коллеги. Я ПЕРВЫЙ ! победил эту тему.
Я вас 3 раза отправлял в Wiki. Вы сопротивлялись . Я сам туда сходил сейчас и прочитал уже получше, чем только заголовки.
Смотрим раздел:
|
Цитата:
|
Маркер UTF-8
Для указания, что файл или поток содержит символы Юникода, в начале файла или потока может быть вставлен маркер последовательности байтов (англ. Byte order mark, BOM), который в случае кодирования в UTF-8 принимает форму трёх байтов: EF BB BF16.
|
Единственный, кто в этой теме был максимально близок к решению -- это voraa !
Его цитата : Я опять искал в Тотале просмотрщик HEX -- нет его там. Плагины показывают правильно -- что нет служебных символов.
Что в Wiki написано ? ТРИ БАЙТА. Я делаю "Кодировать в UTF-8 с BOM" и файл увеличивается на ТРИ БАЙТА. Это победа !
Я уже все понял . Сразу его на хостинг . Смотрим новую редакцию
Все прекрасно ! Сервер видит BOM и ставит правильную кодировку.
Свои способности по вычислению всех кодировок мира -- оцените сами  . Эта тема разрослась на 4 страницы -- это ваша вина
Аплодисменты voraa и мне немного
Последний раз редактировалось seregadushka, 31.07.2024 в 01:49.
|
|
31.07.2024, 03:00
|
|
Профессор
|
|
Регистрация: 19.01.2012
Сообщений: 499
|
|
|
Сообщение от seregadushka
|
Я даю тебе гарантию . что сейчас нет никакой последовательного чтения.
UTF-8, -16, -32 имеет 4 байта на каждый символ. У всех троих одинаково.
|
:facepalm:
Почитай ещё википедию дальше заголовков, знаток кодировок )))
|
Сообщение от seregadushka
|
|
Я вас 3 раза отправлял в Wiki. Вы сопротивлялись . Я сам туда сходил сейчас и прочитал уже получше, чем только заголовки.
|
Это просто шедевр  |
|
31.07.2024, 03:30
|
|
Аспирант
|
|
Регистрация: 10.07.2024
Сообщений: 55
|
|
|
я люблю подтексты, вижу тебе понравилось тоже.
Но ты же за своим зубоскальством не признаешься, что про Маркер кодировки и не слышал, с 80-х годов. Куда и нас пытался затянуть своим нафталином.
|
|
31.07.2024, 06:21
|
|
Профессор
|
|
Регистрация: 19.01.2012
Сообщений: 499
|
|
|
seregadushka,
Если знатоку кодировок от этого полегчает, могу признаться что не знал о том, что браузеры смотрят на этот BOM.
Однако я не считаю незнание постыдным, в конце-концов для того этот форум и существует чтоб обмениваться знаниями. Постыдным я считаю нести полную ахилесицу и что-то гарантировать когда сам даже википедию по теме не прочитал дальше заголовков...
А хамство вообще отбивает всякое желание общаться, не то что помогать.
|
|
31.07.2024, 07:25
|
 |
Профессор
|
|
Регистрация: 03.02.2020
Сообщений: 2,782
|
|
|
Сообщение от seregadushka
|
|
Я опять искал в Тотале просмотрщик HEX -- нет его там.
|
У меня есть. Открываем просмотрщик файла по F3. Далее меню -> вид -> шеснадцатеричный |
|
31.07.2024, 07:31
|
|
Профессор
|
|
Регистрация: 03.02.2020
Сообщений: 2,782
|
|
|
Сообщение от seregadushka
|
Я делаю "Кодировать в UTF-8 с BOM" и файл увеличивается на ТРИ БАЙТА. Это победа !
Я уже все понял . Сразу его на хостинг .
|
Весь вопрос в том, будет ли файл js не только показываться, но и работать с этим маркером?
|
Сообщение от seregadushka
|
|
UTF-8, -16, -32 имеет 4 байта на каждый символ.
|
utf-8 переменное число байт на символ. От 1 до 4.
Так же и Big-5. 1 или 2 байта на символ.
Последний раз редактировалось voraa, 31.07.2024 в 07:55.
|
|
|
|






